
Deno, Web Streams API で Local LLM と音声通話するWebシステムを開発している
開発中のもの
最近時々見かけるようになった、AIと音声通話できるやつを作ってみた。
既存サービスとの違い、特徴としては
- 外部APIを使わず、自宅サーバーのローカルGPUのみで動作
- Web Streams API を活用してリアルタイム処理を実現
- Backend: Deno, Hono, Kysely, PostgreSQL
- Frontend: Node, Vite, React
大まかなロジック
- 人間の声をブラウザのマイク機能で取得してサーバーに Web Streams で送る
- サーバー側で音声データを Faster Whisper を用いてテキスト化する
- テキストをリアルタイムにフロントエンドで取得
- テキストをローカルLLM (Ollama) にプロンプトとして渡す
- ローカルLLMからの実行結果をリアルタイムにフロントエンドに送信
- フロントエンドでテキストを読み上げ
リアルタイム処理
同期処理とかストリーミング処理などともいう。 フロントエンドとバックエンドでデータのやり取りをする際に、少しずつデータを送ることでタイムラグを少なくしてシステムが動くようにする技術のこと。
リアルタイム処理の実装方法
Webシステムのリアルタイム処理について調べると WebSocket に関する情報がたくさん出てくる。
WebSocket のメリット・デメリット
- WebSocket のメリット
- sockert io などのライブラリを使うと簡単に実装できる
- 古いブラウザでも動く
- 使っている人が多いのかドキュメントが豊富
- WebSocket のデメリット
- 双方向通信なので通信量が多い
- ws/wssというプロトコルを使うのでサーバー側で http/https とは別の設計が必要になる
WebStreams のメリット・デメリット
- WebStreams のメリット
- 単方向通信なので通信量を抑えることができる
- http/https で扱うことができるのでサーバーに特別な実装が不要
- WebStreams のデメリット
- 使ってる人が少ないのかドキュメントが少ない(ほとんどMDNだけかも)
- 古いブラウザでは動かないことがある
今回は WebStreams を採用
WebStreams を使ったことがなかったのでやってみたかったというのが一番大きな理由(というかそのためにこのシステムを作っている)なのだが、WebSocketsは意外と気難しいやつだと思っていて、一見気楽に実装できて良いのだが本番環境まで含めて考えると通信量などの問題もあり使いこなすのが難しいという感触がある。
WebStreams API とは何か?
- Readable Stream, Writable Stream, Transform Stream を使ってデータのやり取りができる。
- これらの Stream はシェルコマンドのように pipe してつなげることができるため、すっきりしたコードを書くことができて嬉しい。
- Web標準の機能であるから今どきのブラウザ、そしてDenoで活用することができる
- Node.js は歴史的な経緯により Deno ほど綺麗な実装になっていない
詳しくは MDN 参照 https://developer.mozilla.org/en-US/docs/Web/API/Streams_API
WebStreams API はどこで使われているか?
- fetch の Response Body
- Hono の Streaming Helper
- Deno の IO や HTTP リクエストなど
作成するシステムの概要
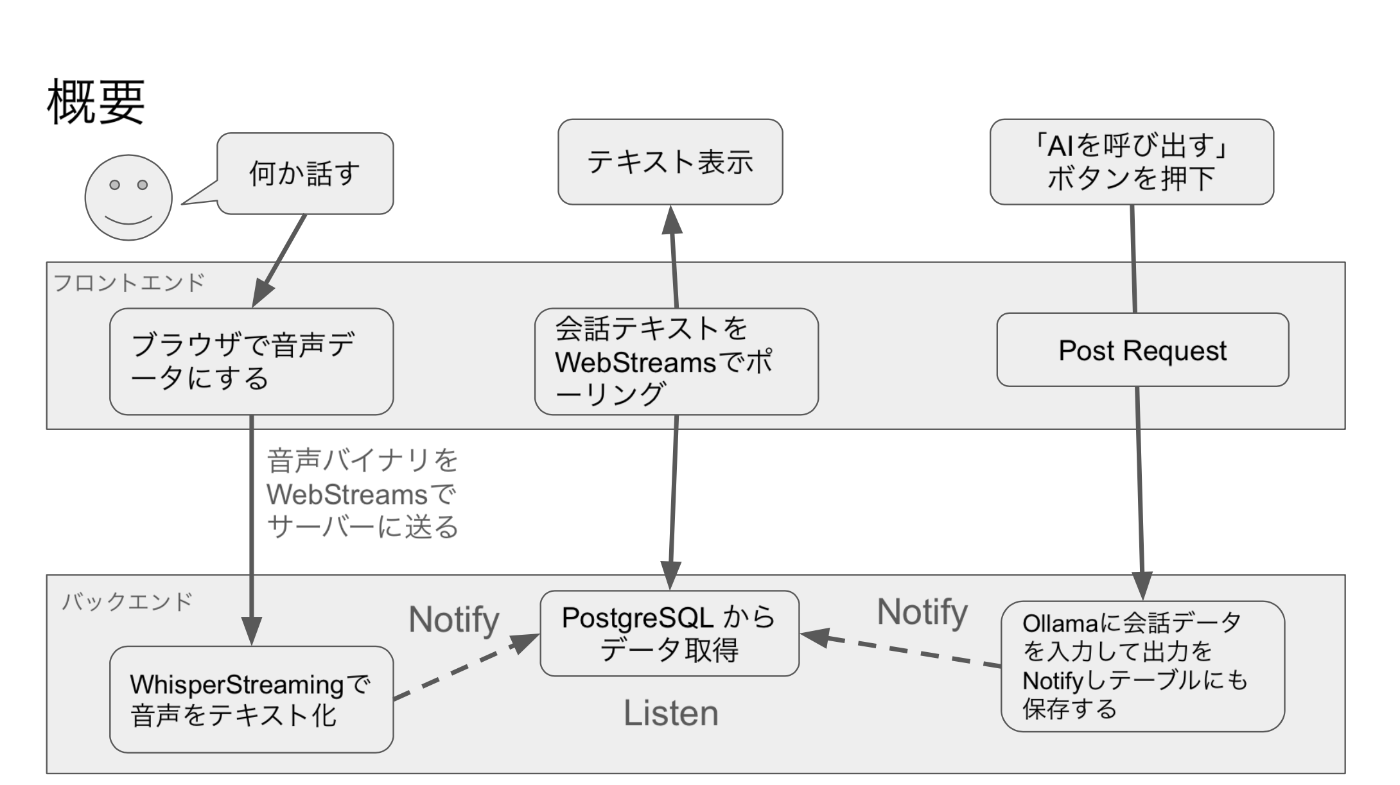
人の声をテキスト化する部分
フロント側の処理。音声データを取得してバックエンドに ReadableStream を使って送信する。
import { jwtTokenAtom } from "@/atoms/current-user";
import { httpClient } from "@/libs/http-client";
import { Box, Button } from "@chakra-ui/react";
import { useMutation } from "@tanstack/react-query";
import { useAtom } from "jotai";
import { useRef } from "react";
type AudioStreamerProps = {
talkId: string;
};
export const AudioStreamer = ({ talkId }: AudioStreamerProps) => {
// 音声データの取得用の Ref
const mediaRecorderRef = useRef<MediaRecorder | null>(null);
const streamControllerRef =
useRef<ReadableStreamDefaultController<Uint8Array> | null>(null);
const [jwtToken] = useAtom(jwtTokenAtom);
const { mutate, isPending } = useMutation({
mutationFn: async (audioStream: ReadableStream<Uint8Array>) => {
return await httpClient({ jwtToken })
.post(`talks/${talkId}/stream`, {
body: audioStream,
timeout: false,
})
.text();
},
onSuccess: (data) => {
console.log(data);
},
onError: (error) => {
console.error(error);
},
});
// 音声データを取得してサーバーにリクエストする
const startRecording = async () => {
try {
// マイクへのアクセスをリクエスト
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
// MediaRecorderの作成
const options = {
mimeType: "audio/webm; codecs=opus", // サポートされているmimeTypeを指定
};
const mediaRecorder = new MediaRecorder(stream, options);
mediaRecorderRef.current = mediaRecorder;
// ReadableStreamの作成
const audioStream = new ReadableStream<Uint8Array>({
start(controller) {
// コントローラを保存して、後でデータをエンキューする
streamControllerRef.current = controller;
},
});
// dataavailableイベントのハンドリング
mediaRecorder.addEventListener("dataavailable", async (event) => {
if (event.data && event.data.size > 0) {
// BlobをArrayBufferに変換
const arrayBuffer = await event.data.arrayBuffer();
// ArrayBufferをUint8Arrayに変換
const chunk = new Uint8Array(arrayBuffer);
// ReadableStreamにチャンクをエンキュー
streamControllerRef.current?.enqueue(chunk);
}
});
// stopイベントのハンドリング
mediaRecorder.addEventListener("stop", () => {
// ReadableStreamをクローズ
streamControllerRef.current?.close();
});
// 録音開始(100msごとにデータを収集)
mediaRecorder.start(100);
// ReadableStreamをAPIに送信
mutate(audioStream);
} catch (error) {
console.error("マイクへのアクセスエラー:", error);
}
};
const stopRecording = () => {
mediaRecorderRef.current?.stop();
};
return (
<Box>
<Button colorScheme="red" onClick={startRecording} isLoading={isPending}>
録音
</Button>
<Button
colorScheme="blue"
onClick={stopRecording}
isDisabled={!isPending}
>
停止
</Button>
</Box>
);
};
バックエンドでは、ReadableStreamを受け取って whisper_streaming のサーバー(これは別途立ち上げておく)に音声データを渡し、テキストデータを受け取る。
app.post("/:id/stream", permissionChecker("talks"), async (c) => {
// 音声データをReadableStreamで取得する
const stream = c.req.raw.body as ReadableStream;
const talkId = Number(c.req.param("id"));
const user = c.get("currentUser");
if (stream) {
// whisper streaming は サンプリングレートなどに指定があるため FFmpeg で変換する
// これは Web Streams API でパイプできる
const ffmpeg = new Deno.Command("ffmpeg", {
args: [
"-i",
"pipe:0", // 標準入力からデータを受け取る
"-ar",
"16000", // サンプリングレートを16000Hzに設定
"-ac",
"1", // モノラルに設定
"-sample_fmt",
"s16", // サンプルフォーマットをs16に設定
"-f",
"wav", // 出力フォーマットをWAVに設定
"pipe:1", // 標準出力にデータを出力
],
stdin: "piped",
stdout: "piped",
stderr: "piped",
});
const ffmpegProcess = ffmpeg.spawn();
stream.pipeTo(ffmpegProcess.stdin);
const convertedAudioStream = ffmpegProcess.stdout;
// WhipserStreamingServer は TCP サーバーなので Deno.connect で接続できる
// これも Web Streams でパイプできる
const whisper = await Deno.connect({
hostname: Deno.env.get("WHISPER_HOST") || "localhost",
port: Number(Deno.env.get("WHISPER_PORT")) || 43001,
});
convertedAudioStream.pipeTo(whisper.writable);
const reader = whisper.readable.getReader();
const decoder = new TextDecoder("utf-8");
let sentence = "";
const sentenceIdentifier = crypto.randomUUID();
try {
// Streams からテキストデータを受け取って、DBに保存したり通知したりする
while (true) {
const { done, value } = await reader.read();
if (done) {
break;
}
const text = decoder.decode(value);
// 先頭に数字が入っているので削除
const wordText = text.replace(/^[\d\s]+/, "").replace(/\n/g, "");
if (wordText.length > 0) {
sentence += wordText;
// 後述のGETリクエストでテキストデータを取得できるようにするためにNotifyする
await notify("words_inserted", {
id: crypto.randomUUID(),
talkId,
userId: user.id,
words: wordText,
sentenceIdentifier,
});
await modelWords.create({
talkId,
userId: user.id,
words: wordText,
sentenceIdentifier,
});
}
}
} catch (error) {
if (error instanceof Deno.errors.Interrupted) {
customLogger("POST クライアントが接続を閉じました。");
}
}
return c.text("completed", 200);
}
return c.text("ストリームが存在しません", 400);
});
新しいテキストができた時にフロントで取得する部分
フロントではAIと話すページを開いたときにバックエンドに対してGETリクエストを出して、 過去の会話履歴を取得するようにしている。 このリクエストをStreamで繋いだままにしておいて、新しいデータが入れば取得するようにしておく
const [words, setWords] = useState<Word[]>([]);
useEffect(() => {
const fetchStream = async () => {
// 次のエンドポイントはReadableStreamを返す
const response = await httpClient({ jwtToken }).get(
`talks/${talkId}/stream`,
);
const stream = response.body;
if (!stream) {
console.error("このブラウザはストリーミングをサポートしていません。");
return;
}
const reader = stream.getReader();
const decoder = new TextDecoder("utf-8");
try {
while (true) {
const { done, value } = await reader.read();
if (done) {
console.log("done!");
break;
}
// 新しいデータを受け取ったら Words 配列にいれる
// (なるべく連続するデータは同じフキダシに入れたいのでちょっとコードがごちゃごちゃしている)
const chunk = decoder.decode(value, { stream: true });
const json = JSON.parse(chunk);
const lastWord = json[0];
if (lastWord?.assistantId != null) {
speak(lastWord.words);
}
setWords((prev) => {
const newArray = [...json, ...prev];
const result = newArray.reduce((acc, cur) => {
const key = cur.sentenceIdentifier;
acc[key] = {
id: key,
userId: cur.userId,
talkId: cur.talkId,
words: acc[key]
? `${cur.words}${acc[key].words}`.replace(/\n/g, "")
: cur.words.replace(/\n/g, ""),
sentenceIdentifier: key,
};
return acc;
}, {});
return Object.values(result);
});
}
} catch (error) {
console.error("ストリームの読み取り中にエラーが発生しました:", error);
}
};
fetchStream();
}, [jwtToken, talkId]);
// words 配列を表示する処理が続く
バックエンドでは PostgreSQL の Notify/Listen 機能を使って Channel のようなことをする。 これにより、新しいデータが追加されたらフロントエンドに送る。
app.get("/:id/stream", permissionChecker("talks"), async (c) => {
const talkId = Number(c.req.param("id"));
const words = await modelWords.findAllByTalkId(talkId);
const wordsJson = JSON.stringify(words);
// stream を返すのでクライアントが接続を切らない限りデータを渡し続けることができる。
return streamText(c, async (s) => {
await s.writeln(wordsJson);
// words_insterted という channel にJSONテキストが入ってくるのでそれを監視する
// WARN channel 名に talkId を入れたほうが他の会話のデータを誤って取得せずに済みそう
await listen("listen words_inserted", async (msg) => {
if (msg.channel !== "words_inserted") {
return;
}
const word = JSON.parse(msg.payload);
await s.write(JSON.stringify([word]));
});
s.onAbort(() => {
customLogger("GET クライアントが接続を閉じました。");
});
while (true) {
await s.sleep(1000);
}
});
});
listen と notify 関数の実装は次のような感じ
import { CamelCasePlugin, Kysely, PostgresDialect, sql } from "kysely";
import Pool from "pg-pool";
import type { DB } from "./database-types.ts";
import { clerk } from "./libs/clerk.ts";
export const pool = new Pool({
connectionString:
Deno.env.get("DENO_ENV") === "test"
? Deno.env.get("TEST_DB_URL")
: Deno.env.get("DATABASE_URL"),
max: 20,
idleTimeoutMillis: 30000,
connectionTimeoutMillis: 2000,
});
const dialect = new PostgresDialect({
pool,
});
export const db = new Kysely<DB>({
dialect,
plugins: [new CamelCasePlugin()],
log: (log) => {
if (log.level === "query") {
clerk.info("SQL", log.query.sql);
}
},
});
export async function notify(channel: string, obj: object) {
return await sql`select pg_notify(${channel}, ${JSON.stringify(obj)})`.execute(
db,
);
}
export async function listen(
listenChannel: string,
callback: (msg: { channel: string; payload: string }) => void,
) {
const pgClient = await pool.connect();
pgClient.on("notification", callback);
return await pgClient.query(listenChannel);
}
Local LLM へのリクエストとレスポンス
会話データができたので、これをもとにプロンプトを作成してローカルLLMにリクエストする。
import { Button } from "@chakra-ui/react";
export function TalkToAI({
assistantMutate,
assistantIsPending,
}: { assistantMutate: () => void; assistantIsPending: boolean }) {
return (
<Button
colorScheme="blue"
onClick={() => assistantMutate()}
isLoading={assistantIsPending}
>
AIをよびだす
</Button>
);
}
// assistantMutate の中身
const { mutate: assistantMutate, isPending: assistantIsPending } =
useMutation({
mutationFn: async () =>
await httpClient({ jwtToken }).post(`talks/${talkId}/assistant_chat`, {
timeout: false,
}),
onSuccess: () => {
//
console.log("ok");
},
onError: (error) => {
console.error(error);
},
});
現状、AI呼び出しのトリガーはボタンにしてある。 将来的にはユーザーが話し終わったら自動で処理するようにしたい。
バックエンドでは talks/${talkId}/assistant_chat にリクエストがあると、次の処理を行う。
- 次の情報からLLMのプロンプトを作成する
- 直近数回の人間とAIの会話データ
- AIの人格設定データ
- ローカルLLMサーバー (Ollama を使用) にプロンプトを投げる
- レスポンスをStreamで受け取り、DBにNotify、保存
app.post("/:id/assistant_chat", permissionChecker("talks"), async (c) => {
const talkId = Number(c.req.param("id"));
const user = c.get("currentUser");
const talk = await modelTalks.findById({
talkId,
userId: user.id,
});
if (!talk) {
return c.json({ message: "Talk not found" }, 404);
}
// 直近数回の会話を取得
const words = await modelWords.findLatestByTalkId(talkId);
// 人間とAIの会話によって role を切り替えながらLLMのプロンプトを作成
let messages = words
.map((word) => ({
role: word.userId == null ? "assistant" : "user",
content: `${word.words}`,
}))
.reverse();
// AIの人格設定は system role で渡す
messages = [
...messages,
{ role: "system", content: talk.assistant.personality },
];
// Ollama で動いているローカルLLMにリクエストする
const response = await ky.post(`${Deno.env.get("OLLAMA_URL")}/api/chat`, {
json: {
model: talk.assistant.model,
messages,
stream: true,
},
});
// ローカルLLMサーバーからのレスポンスをchannelに通知したり、保存したりする
const reader = response.body?.getReader();
const decoder = new TextDecoder("utf-8");
const sentenceIdentifier = crypto.randomUUID();
let text = "";
let textChank = "";
while (reader && true) {
const { done, value } = await reader.read();
if (done) {
break;
}
const jsonText = decoder.decode(value, { stream: true });
const json = JSON.parse(jsonText);
textChank += json.message.content;
if (textChank.length > 20) {
await notify("words_inserted", {
id: crypto.randomUUID(),
talkId: talk.id,
assistantId: talk.assistantId,
words: textChank,
sentenceIdentifier,
});
text += textChank;
textChank = "";
}
}
if (textChank.length > 0) {
await notify("words_inserted", {
id: crypto.randomUUID(),
talkId: talk.id,
assistantId: talk.assistantId,
words: textChank,
sentenceIdentifier,
});
text += textChank;
textChank = "";
await modelWords.create({
talkId,
assistantId: talk.assistantId,
words: text,
sentenceIdentifier,
});
}
return c.json({ msg: text });
});
AIからのレスポンステキストの読み上げ
ひとまずブラウザの機能で読み上げているだけ
function speak(text: string) {
// SpeechSynthesisUtteranceのインスタンスを作成
const utterance = new SpeechSynthesisUtterance();
utterance.text = text;
utterance.lang = "ja-JP";
// 音声を再生
window.speechSynthesis.speak(utterance);
}
新しいテキストを取得した際に、AIからの発言であれば上記の関数を使って読み上げる。
今後の展望
テキスト読み上げが地味なので VOICEVOX などをつかって音声データをサーバーで作成し、 フロントに送るようにしたい。 これもStreamを利用してリアルタイムにやりたいので、そんな感じの仕組みを作成中。
すべてのソースコードの公開は全体が完成したらします。